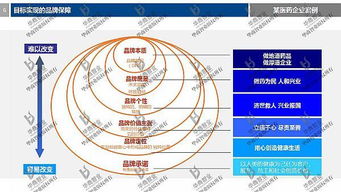
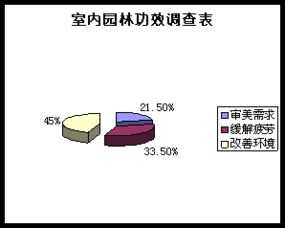
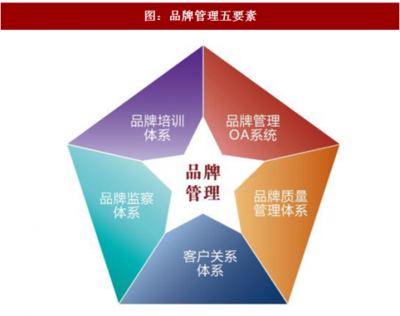
在當今競爭激烈的市場環(huán)境中,品牌互動營銷已成為企業(yè)提升用戶參與度和忠誠度的重要手段。互動營銷通過建立品牌與消費者之間的雙向溝通,增強了用戶體驗,從而推動銷售增長和品牌影響力的擴大。以下將詳細探討品牌互動營銷的兩種主要方式:社交媒體互動營銷和體驗式互動營銷。
一、社交媒體互動營銷
社交媒體互動營銷是利用社交平臺(如微信、微博、抖音等)與用戶進行實時互動的方式。這種方式的核心在于通過內(nèi)容分享、評論回復、話題討論等形式,拉近品牌與消費者的距離。企業(yè)可以通過定期發(fā)布吸引人的帖子、舉辦線上活動(如抽獎、投票、挑戰(zhàn)賽)來激發(fā)用戶參與。例如,許多品牌會在微博上發(fā)起話題討論,鼓勵用戶分享自己的故事,這不僅增加了品牌的曝光率,還通過用戶生成內(nèi)容(UGC)強化了品牌形象。社交媒體互動營銷的優(yōu)勢在于能夠快速響應(yīng)市場變化,精準觸達目標受眾,并以較低成本實現(xiàn)病毒式傳播。這種方式需要持續(xù)的內(nèi)容創(chuàng)新和社區(qū)管理,以維持用戶的長期興趣。
二、體驗式互動營銷
體驗式互動營銷強調(diào)通過沉浸式體驗,讓消費者親身參與品牌的互動過程,從而建立情感連接。這種方式常見于線下活動、虛擬現(xiàn)實(VR)體驗、快閃店或品牌展覽等。例如,一些汽車品牌會組織試駕活動,讓潛在顧客親自駕駛,體驗產(chǎn)品的性能;或者科技公司通過VR技術(shù)展示產(chǎn)品功能,讓用戶在虛擬環(huán)境中互動。體驗式互動營銷的優(yōu)點是能夠深化品牌記憶,通過感官刺激增強用戶對品牌的正面印象,并促進口碑傳播。它特別適用于需要展示復雜產(chǎn)品或服務(wù)的行業(yè),但實施成本較高,且需要精心策劃以確保用戶體驗的流暢性。
社交媒體互動營銷和體驗式互動營銷是品牌互動營銷的兩大支柱。前者側(cè)重于線上平臺的即時互動和內(nèi)容傳播,后者則注重線下或虛擬環(huán)境中的深度體驗。在實際應(yīng)用中,企業(yè)可以根據(jù)品牌定位、目標受眾和資源情況,靈活結(jié)合這兩種方式,以構(gòu)建全面的互動營銷策略。例如,一個時尚品牌可能同時利用社交媒體進行話題營銷,并在線下舉辦快閃店活動,從而全方位提升用戶參與度。通過這種方式,品牌不僅能增強與消費者的情感紐帶,還能在激烈的市場競爭中脫穎而出。